Author: Stephanie Ding
Mentor: Julian Bunn
Editor: Sherry Wang
Abstract
Botnets are collections of connected, malware-infected hosts that can be controlled by a remote attacker. They are one of the most prominent threats in cybersecurity, as they can be used for a wide variety of purposes including denial-of-service attacks, spam or bitcoin mining. We propose a two-stage, machine-learning based method for distinguishing between botnet and non-botnet network traffic, with the aim of reducing false positives by examining both network-centric and host-centric traffic characteristics. In the first stage, we examine network flow records generated over limited time intervals, which provide a concise but partial summary of the complete network traffic profile, and use supervised learning to classify flows as malicious or benign based on a set of extracted statistical features. In the second stage, we perform unsupervised clustering on internal hosts involved in previously identified malicious communications to determine which hosts are most likely to be botnet-infected. Using existing datasets, we demonstrate the feasibility of our method and implement a proof-of-concept, real-time detection system that aggregates the results of multiple classifiers to identify infected hosts.
Introduction
In the twenty-first century, networked devices have become an integral part of any business or organization; this is because they support an extensive number of applications and services such as access to the World Wide Web, multimedia sharing, file storage, and instant messaging and email. The growing number and complexity of networked devices means that they are increasingly being targeted by cybercriminals, who exploit vulnerable devices for malicious purposes – particularly due to the advent of the Internet of Things (IoT), which represent new potential attack vectors as modern malware is now capable of taking over devices such as surveillance cameras and ‘smart’ household devices with built-in network capabilities. One of the common uses for compromised devices is to integrate them into a botnet – a collection of connected hosts (“bots” or “zombies”) infected with malware that allows them to be controlled by a remote host (the “botmaster”). Botnets are powerful assets for attackers due to their versatility as they can be employed for a wide variety of purposes, such as generating a large amount of traffic towards an existing service in an attempt to prevent legitimate traffic from being processed (known as Distributed Denial-of-Services or DDoS attacks), email phishing and spam, and with the advent of cryptocurrencies in recent years, distributed bitcoin mining, making them one of the most prominent threats in the cybersecurity field.
Presently, botnets are responsible for the majority of online email spam, identity theft, phishing, fraud, ransomware and denial-of-service attacks, and are substantial sources of damage and financial loss for organizations and business. Taking action to neutralize the potential impact and harmful behaviors of botnets have become essential steps in almost all malware mitigation strategies, resulting in the need for rapid and effective identification of botnet infections.
Background and related work
Historically, botnet detection was achieved through setting up “honeypots” or “honeynets” – security mechanisms that appear to contain data and are a legitimate part of some network, but are in fact isolated systems designed to detect and/or counteract attempts at intrusion into the network – and developing specific signatures for various types of botnets in order to defend against future attacks of the same type. These signatures are then used for payload analysis techniques such as deep packet inspection (DPI), which requires individually inspecting every packet transmitted on the network and matching for malicious packet signatures. While payload inspection techniques usually achieve a high level of identification accuracy, they have several downsides. Detailed analysis at the packet level often exposes private information sent by network users, signature-based detection methods are slower to adapt to new and emerging botnet attacks, and the development of large-scale honeypots is a significant time and economic investment. Furthermore, inspecting each packet sent through the network is extremely time and resource-intensive due to the sheer volume of packets that must be processed, making packet-inspection techniques unsuitable for real-time detection.
Network-centric, traffic analysis-based schemes have become increasingly popular as an alternative to signature-based detection schemes as they do not suffer from the same limitations of payload inspection techniques. These methods often focus on examining network flows, which is conventionally defined as a sequence of packets over some period of time, grouped by source internet protocol (IP) address, source port, destination IP address, destination port, and protocol – essentially a summary of a communication channel between two hosts. The underlying assumption of flow-based network analysis is that botnet traffic is distinguishable from regular network traffic in some manner, which can be determined through statistical features irrespective of individual packet contents. This makes a flow-based approach less susceptible to encryption or obfuscation techniques, as well as vastly reducing the amount of data that needs to be processed. Furthermore, many types of bots may exhibit similar patterns of behavior despite having different signatures, making a flow-based approach more generalizable.
Strayer et al. [1] were one of the first to demonstrate the use of supervised machine learning to identify botnets using internet relay chat (IRC) for communication. They were able to successfully classify transmission control protocol (TCP) flows with low (< 3%) false positive and negative rates, despite the fact that their method modeled TCP as the primary communication channel of botnet traffic. Similarly, Masud et al. [2] were able to detect botnet traffic by using a flow-based machine learning approach and performing classification on host-level forensic and deep packet inspection in order to differentiate between benign and botnet traffic. Saad et al. [3] proposed a new approach of botnet detection, focused on identifying traffic during a period of the botnet life cycle prior to the attack being launched (termed the ‘command and control’ or C&C stage by the authors) and applied machine learning to this subset of network traffic in order to detect peer-to-peer (P2P) botnets, utilizing both host-based and flow-based traffic features. Camelo et al. [4] presented a new method of identifying botnet activity by appropriating features from several data feeds such as domain name server (DNS) domain responses, live communication directed to C&C servers, and performing machine learning on a graph representation of the data, allowing them to identify botnets as singly-connected components of known malicious servers (domains) and infected machines (IPs) to a reasonable degree of accuracy. The success of these methods confirms that botnet traffic exhibits certain characteristics and communication patterns that can be exploited using classification techniques.
Approach

Figure 2.1.1. Overview of our detection method in a proposed system.
Our detection method contained two stages, allowing us to examine both network-centric features of the traffic and similarities in traffic generated by multiple infected hosts. For each window, we extracted a set of flow features from each flow and then applied a two-stage machine learning process to determine infected network hosts. In stage 1, we utilized supervised learning by training a classifier on existing datasets to perform binary classification and determine which flows are likely to be botnet flows. In stage 2, we applied unsupervised learning and clustered the hosts involved in the identified botnet flows into two clusters, benign and anomalous, based on a separate set of host-based features. We detected whether a host is infected or not by examining a sequence of windows and analyzing the evolution of the host’s cluster membership over time. Finally, to demonstrate the potential real-world applications of our detection method, we built a proof-of-concept application designed for use in a network monitoring situation and illustrate how our detection scheme can be applied for real-time detection.
Method
Datasets
The dataset used was the CTU-13 dataset [5] which is a publicly available, labelled dataset developed by researchers at the Czech Technical University containing thirteen separate scenarios of mixed botnet, background, and normal traffic. In each scenario, the researchers captured network traffic of the entire university network at an edge router for a period of time, during which a botnet infection was simulated on one or several networked virtual machines by running a specific type of malware. Each scenario contained a packet capture (.pcap) of the botnet traffic only, and a truncated .pcap of the full packet capture which included the complete headers of each packet but removed packet payloads to protect the anonymity of network users. The full packet capture was also processed using the utility Argus (the Audit Record Generation and Utilization System) [6] to generate bidirectional network flow summaries (in .binetflow format), with a limited number of features output for each flow. Each .binetflow file was labelled by the researchers to identify particular communications as either a botnet flow, a normal flow, or a background flow.
We examined seven of the thirteen scenarios – scenarios 5, 6, 7, 9, 11, 12 and 13 – with a particular emphasis on scenario 9 as it was one of the larger captures and contained the most infected hosts. The selected scenarios covered a diverse range of botnets that vary in the number of infected network hosts, protocols, and malicious actions, and were representative of a large majority of behaviors found in modern botnets. Figure 3.2.1 describes each scenario in further detail:
| Scenario | Botnet name | Infected hosts | Capture duration (hrs) | Protocol | Behaviors and characteristics |
| 5 | Virut | 1 | 11.63 | HTTP | Spam, port scan, web proxy scanner. |
| 6 | Menti | 1 | 2.18 | HTTP | Port scan, proprietary C&C, RDP. |
| 7 | Sogou | 1 | 0.38 | HTTP | Connects to Chinese hosts. |
| 9 | Neris | 10 | 5.18 | IRC | Spam, click fraud, port scanning. Bitcoin miner. |
| 11 | Rbot | 3 | 0.26 | IRC | ICMP DDoS. |
| 12 | NSIS.ay | 3 | 1.21 | P2P | Synchronization. |
| 13 | Virut | 1 | 16.36 | HTTP | Spam, port scan, captcha and web mail. |
Figure 3.1.1. Details of selected scenarios in the CTU-13 dataset.
Stage 1: Supervised learning (binary classification)
3.3.1 Flow extraction and feature selection
A feature is a characteristic of a flow over a period of time, which may either be extracted directly from packet headers (for example, source and destination IP) or calculated from the packet captures (such as packet interarrival time, standard deviation of packet size or ratio of packet asymmetry between source and destination). We utilized the flow exporter Argus (also used by the authors of the CTU-13 dataset) which is capable of generating bidirectional network flow data generator with detailed statistics about each flow, including reachability, load, connectivity, duration, rate, jitter and other metrics. 40 features were selected to describe each flow, based on domain knowledge and some assumptions about the behavior of botnets.

Figure 3.1.2. The 40 selected flow features ranked by relative importance in classification.
The features that comprised the standard 5-tuple (source IP address, source port, destination IP address, destination port, protocol) were used to define the flow ID for each flow. Almost all features were numeric in nature, with the exception of two categorical values direction and state, which were mapped to discrete integer values through a direct enumeration of unique values. As we wished to select a set of network-agnostic, universal features for the flow feature vector, the features that comprised the 5-tuple were not included in the feature vectors to train the classifiers, as different networks may use a variety of ports and services and have different IP addresses.
3.3.4 Training models on limited time intervals
For each scenario, a training dataset was generated with a ratio of 1:10 botnet to non-botnet flows. This ratio was chosen due to the highly imbalanced nature of the captures, which contained significantly more background and normal flows (around 90% to 97% of the entire dataset) compared to botnet flows (around 0.15% to 8.11%). We found the ratio of 1:10 to be sufficiently similar to the real datasets while containing adequate samples of botnet flows to obtain good classifier accuracy, although other models trained with different botnet to non-botnet flow ratios demonstrated that it is possible to alter model performance and attain a higher TPR at the cost of more false negatives, and vice-versa.
Dataset generation was performed by first splitting each packet capture into 300 second windows. Each window had a 150 second overlap with the previous window, to maintain some temporal continuity between flows split across multiple windows. Argus was then used to generate the flows for each window and compute 36 features for each flow. As the captures vary in length, some contain significantly more flows than others. On shorter captures, a training dataset with 1,000 botnet flow samples and 10,000 non-botnet flow samples was generated, while on longer captures a training dataset containing 10,000 botnet flow samples and 100,000 botnet flow samples was generated. For each capture, a small portion of the generated dataset would then be used for training a supervised learning classifier while the remaining flows were reserved for testing and validation of the trained classifier.
We initially tested a variety of supervised learning algorithms (Naïve Bayes, Support Vector Machines, Decision Trees, Random Forests) on our dataset to explore the differences in classifier performance and to confirm our hypothesis that the selected 40 features facilitated distinction between botnet and non-botnet flows, ultimately selecting to use random forest classifiers due its robustness and superior performance on our dataset. Using the training dataset, a random forest classifier was trained with 100 estimators to perform binary classification on flow feature vectors generated over 300 second windows, i.e. output 0 if it determines a feature vector to be representative of a non-botnet flow, or output 1 if it determines a feature vector to be representative of a botnet flow.
Stage 2: Unsupervised learning (clustering)
Stage 2 of the detection process applied unsupervised learning on the results of stage 1, and examined host-based characteristics, rather than flow-based characteristics. In each window, the classifier was first used to identify potential botnet flows. An internal host is defined as being involved in botnet communications if it is either the source IP or the destination IP of a flow predicted by the classifier as being a botnet flow. For all hosts involved in botnet communications, seven host-based features were computed:
- The total number of predicted botnet flows that the host is involved in.
- The total number of outgoing packets from the host involved in botnet flows.
- The total number of incoming packets from the host involved in botnet flows.
- The total number of incoming bytes from the host involved in botnet flows.
- The total number of outgoing bytes from the host involved in botnet flows.
- The total number of unique destination ports the host is communicating with.
- The total number of unique destination IPs the host is communicating with.
These features were standardized such that the range of values for each feature had a mean of 0 and a standard deviation of 1 and were then used to form a feature vector for each host. Agglomerative hierarchical clustering (a ‘bottom-up’ method of cluster analysis, in which each data point begins in its own cluster, but are progressively merged into other clusters higher up in the hierarchy) was applied on the host feature vectors, using the standard Euclidean distance as the distance metric between vectors and utilizing Ward linkage (minimum variance criterion) which ensures that at each merging step, the pair of clusters that leads to the minimum increase in total inter-cluster variance is chosen.
Evaluation
Results
4.1.1. Stage 1
Due to the imbalanced distribution of botnet and non-botnet flows within the datasets, accuracy alone is not a good predictor of classifier performance as a high accuracy can be achieved simply by classifying the majority of flows as non-botnet due to there being significantly higher numbers of non-botnet flows compared to botnet flows. Thus, in stage 1, the performance of the binary classifier was evaluated with metrics such as the true positive rate and true negative rate instead. Here we define a true positive as a flow vector with a botnet flow ID, during a time window when the botnet is running, that is classified as a botnet flow. Similarly, a true negative is a botnet flow vector with a non-botnet flow ID that is correctly classified as a non-botnet flow.
A separate classifier was trained for each scenario examined, and the performance of the classifier was evaluated on the specific dataset it was trained on. The following table describes the number of flow vectors extracted from each dataset:
| Scenario | Unique botnet flow IDs | Unique normal flow IDs | Unique background flow IDs | Number of windows | Average number of flows per window | Total botnet flow vectors | Total non-botnet flow vectors |
| 5 | 856 | 4631 | 113667 | 13 | 32310 | 2326 | 417704 |
| 6 | 4621 | 7238 | 394056 | 52 | 48911 | 10960 | 2532403 |
| 7 | 44 | 1666 | 103950 | 9 | 47119 | 308 | 423766 |
| 9 | 93438 | 27749 | 1100291 | 125 | 67714 | 435076 | 8029131 |
| 11 | 8155 | 613 | 91436 | 7 | 45301 | 8855 | 308249 |
| 12 | 1972 | 7448 | 265712 | 30 | 40159 | 9234 | 1195532 |
| 13 | 32866 | 27183 | 943512 | 393 | 18136 | 98997 | 7028311 |
Figure 4.1.1. Statistics about flow vectors extracted from each scenario.

Figure 4.1.2. Total TPR/TNR across all scenarios examined. True positive rate (TPR) was calculated as TPR=TPTP+FN and true negative rate (TNR) was calculated as TNR=TNTN+FP. The total TPR/TNR was calculated on the sum total of the true positives and true negatives across all windows in a dataset, while for the average TPR/TNR reflects the average of all individual TPR/TNR values calculated on each window separately.

Figure 4.1.3. Average TPR/TNR across all scenarios examined. As the botnet is not active in the first few windows for many scenarios, these values are calculated only during time windows when the botnet is running.
4.1.2 Stage 2
In unsupervised learning, we made the heuristic assumption that the anomalous/botnet cluster has higher intra-cluster variance, which was true for the datasets examined. The performance evaluation of stage 2 reflects the number of local IP addresses that are correctly clustered. Note that in this context a false negative is a botnet host that was not present in the anomalous cluster during a window when the botnet is running – either as a result of being clustered incorrectly into the majority cluster, or its flows not being identified by the classifier as botnet flows.
Using t-distributed stochastic neighbor embedding (t-SNE), a dimensionality reduction algorithm that facilitates visualization of clustering results, separation between points corresponding to botnet and non-botnet hosts was clearly observed during windows when the botnet was active, despite the clustering algorithm failing to identify the correct clusters in all cases. This indicates an underlying structure and differences between botnet and non-botnet traffic that could potentially be better modelled with other clustering methods in the future.


Figure 4.1.4. t-SNE of host feature vectors on some windows in scenario 9 when the botnet was inactive. Red dots denote true positives, blue dots denote true negatives, red crosses indicate false positives, and blue crosses denote false negatives. A lack of structure in the underlying data is observed and the anomalous cluster consists of a few isolated edge points.


Figure 4.1.5. t-SNE of host feature vectors on some windows in scenario 9 when the botnet was active.
Due to the temporal nature of the windowed captures, the true positive rate, false positive rate, and false negative rate were measured across all time windows for each scenario (Figure 4.1.4). Note that some scenarios (5, 6, 7, 13) only have a single infected host, so if multiple false positives occur this is shown as a false positive rate of >1.
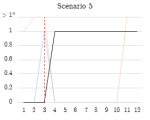
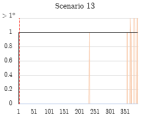
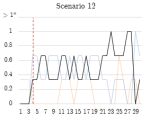
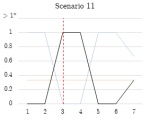
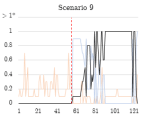
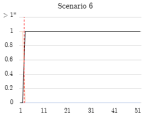

Figure 4.1.6. Graphs of stage 2 TPR/FPR/FNR over time windows.
| Scenario | Total IPs | TP | FP | FN | TN | TPR | TNR | |
| 5 | 252 | 9 | 11 | 1 | 231 | 90.00% | 95.45% | |
| 6 | 513 | 50 | 4 | 0 | 459 | 100.00% | 99.14% | |
| 7 | 173 | 3 | 8 | 2 | 160 | 60.00% | 95.24% | |
| 9 | 5549 | 427 | 151 | 161 | 4810 | 72.62% | 96.96% | |
| 11 | 59 | 11 | 7 | 3 | 38 | 78.57% | 84.44% | |
| 12 | 643 | 44 | 12 | 31 | 556 | 58.67% | 97.89% | |
| 12 | 3471 | 392 | 50 | 0 | 3029 | 100.00% | 98.38% |
Figure 4.1.7. The total true positives, true negatives, false positives and false negatives for each scenario, which is a sum of the respective values across all time windows.
Discussion
The classifier performance in stage 1 demonstrated that the selected 40 features were capable of distinguishing between botnet and non-botnet flows to a high degree of accuracy (> 89%), even if the flows were only generated over fixed-time windows and provided a limited perspective of the entire network traffic. The true negative rate was consistently high, but this is likely a reflection of the nature of the training set, in which there were significantly more non-botnet flows.
The classifier for scenario 12 had a significantly lower total TPR when compared to other scenarios. This may have been due to scenario 12 featuring a P2P botnet, which, unlike a traditional botnet with a single C&C server, communicates with a list of trusted servers (including other infected machines) in a decentralized manner. The traffic was likely to be less structured and have greater variance, appearing more similar to background traffic and thus making the classification task more difficult. In contrast, scenarios 6 and 11, which are a traditional C&C botnet and an ICMP DDoS botnet respectively, were much more likely to have botnet traffic that is more structured and distinguishable from regular network traffic, and thus the classifier trained for these scenarios have better performance.
In stage 2, generally, true infected hosts were consistently clustered into the anomalous cluster after the botnet began running, while non-infected hosts (false positives) were not consistently identified as such across consecutive windows. The detection scheme was highly effective on scenarios 5, 6, and 13, where each contained one infected host, and maintained a TPR of 1.0 throughout the duration of the botnet’s execution. Scenarios 7 and 11 also featured a TPR rate of 1.0 when the bot began running, but the detection rate dropped over subsequent windows. The performance of the detector may have been affected by the relatively short duration of these captures. Scenario 9 featured a more realistic example of botnet traffic on a network, as it contained ten infected hosts. After the botnet begins running, a gradual increase in the detection rate is observed, reaching 1.0 during later stages of the botnet’s execution.
Scenario 12 contained 3 infected hosts. The TPR for scenario 12 fluctuated between 0.33 and 0.66 during the majority of the botnet’s execution, indicating that 1 or 2 of the 3 infected hosts were consistently detected. This may have been due to the lower accuracy of the scenario 12 classifier in stage 1, which impacts the number of flows identified as botnet flows. It is likely that some botnet flows were incorrectly classified by the classifier as benign, resulting in a host not being identified as involved in botnet communications.
Conclusion
The results of this project show that it is possible to distinguish between botnet and non-botnet network flows to a high degree of accuracy (> 0.89 TPR), even if the flows are generated over limited time windows and provide an incomplete representation of the complete network traffic profile. This makes time-limited flows suitable for the purpose of real-time detection. Furthermore, the two-stage process of classification and clustering is able to effectively identify infected hosts for several classes of malware. Although our current clustering method is not able to produce the ideal clusters correctly in all windows, t-SNE visualization of the host data points indicates strong separability between the botnet hosts and non-botnet hosts. This has implications for further research in this area as clustering could be improved by using different algorithms in order to detect the underlying structure.
One limitation of our work is that the classifiers are trained on existing botnet data, making our detection method potentially vulnerable to new and emerging types of botnets which may have different traffic patterns. Furthermore, as we rely on statistical features of flows for classification, attackers may evade detection through varying these characteristics if they are known. Additionally, our criterion for labelling the normal and anomalous cluster is presently only a heuristic that is valid for the datasets we have been examining, and is not true of all networks, and a more robust method of identifying normal and anomalous is necessary to generalize this detection scheme to other types of botnets.
We envision our detection method being used as part of a real-time network monitoring solution. To demonstrate the potential practical applications of our detection method, we have developed a prototype real-time detection system and tested it on CTU scenario 9, successfully identifying all 10 true infected hosts with a minimal number of false positives. For more information, see the project log at https://botnetsurf2017.wordpress.com/ or the Github repository https://github.com/onionymous/botd.
References
[1] W. T. Strayer, D. Lapsely, R. Walsh and C. Livadas, “Botnet detection based on network behaviour,” Advances in Information Security, vol. 36, pp. 1-24, 2008.
[2] M. Masud, T. Al-khateeb, L. Khan, B. Thuraisingham and K. Hamlen, “Flow-based identification of botnet traffic by mining multiple log files,” in First International Conference on Distributed Framework and Applications, 2008.
[3] S. Saad, I. Traore and A. Ghorbani, “Detecting P2P botnets through network behavior analysis and machine learning,” 2011 Ninth Annual International Conference on Privacy, Security and Trust, 2011.
[4] P. Camelo, J. Moura and L. Krippahl, “CONDENSER: A Graph-Based Approach for Detecting Botnets,” 2014.
[5] S. Garcia, M. Grill, H. Stiborek and A. Zunino, “An empirical comparison of botnet detection methods,” Computers and Security Journal, vol. 45, pp. 100-123, 2014.
[6] QoSient, LLC., “Argus: Auditing network activity,” 1 June 2016. [Online]. Available: https://qosient.com/argus/index.shtml. [Accessed 22 September 2017].
[7] Wireshark Foundation, “Wireshark,” 29 August 2017. [Online]. Available: https://www.wireshark.org/. [Accessed 22 September 2017].
[8] S. Garcia, “CTU-Malware-Capture-Botnet-51 or Scenario 10 in the CTU-13 dataset.,” 05 May 2017. [Online]. Available: https://mcfp.felk.cvut.cz/publicDatasets/CTU-Malware-Capture-Botnet-51/. [Accessed 22 September 2017].
[9] A. H. Lashkari, G. Draper-Gil, M. S. Mamu and A. A. Ghorbani, “Characterization of Tor Traffic Using Time Based Features,” in 3rd International Conference on Information System Security and Privacy, Porto, 2017.
[10] L. v. d. Maaten and G. Hinton, “Visualizing Data using t-SNE,” Journal of Machine Learning Research, vol. 9, pp. 2579-2605, 2008.
[11] Riverbank Computing Limited, “PyQt4 Download,” 2016. [Online]. Available: https://www.riverbankcomputing.com/software/pyqt/download. [Accessed 22 September 2017].
[12] L. Campagnola, “PyQtGraph,” 2012. [Online]. Available: https://github.com/pyqtgraph/pyqtgraph. [Accessed 22 September 2017].
[13] S. Zander and C. Schmoll, “netmate-flowcalc,” 4 December 2016. [Online]. Available: https://github.com/DanielArndt/netmate-flowcalc. [Accessed 22 September 2017].
[14] S. Burschka, B. Dupasquier and A. Fiaux, “Tranalyzer,” 23 June 2017. [Online]. Available: https://tranalyzer.com/. [Accessed 22 September 2017].
Acknowledgments
I would like to acknowledge my mentor, Dr. Julian Bunn for giving me the opportunity to participate in the Caltech Summer Undergraduate Research Fellowship (SURF) program. Thank you so much for your endless patience, continued support, insight and guidance throughout this project.
I would also like to thank Bruce Nickerson and his family for the honor of being named as the J. Weldon Green SURF Fellow for 2017. Thank you for your commitment to supporting aspiring undergraduate researchers at Caltech – this project was only made possible by your generous support and contribution towards the SURF program.
Finally, I would also like to thank Arun Viswanathan and Dr. K. Mani Chandy for their assistance and input on technical aspects of this project.
