Author: Annabel Gomez
Mentor: Dr. Xiaoqing Pi
Editor: Suchitra Dara
Introduction
Solar activities, such as solar flares and coronal mass ejections, produce perturbations in solar wind and the interplanetary magnetic field (IMF). These perturbations interact with the Earth’s magnetosphere, resulting in geomagnetic storms, charged particle precipitation, and plasma convection in the high-latitude ionosphere. These events can produce various ionospheric disturbances depending on location, geomagnetic conditions, presence of ionospheric currents, plasma convection, etc. The ionospheric disturbances, including the process of plasma instabilities, give rise to irregular structures in ionospheric density distribution, also known as ionospheric irregularities.
The Wide Area Augmentation System (WAAS) was developed by the Federal Aviation Administration (FAA) of the United States to support aviation navigation [1]. WAAS provides a ground-based global positioning system (GPS) tracking network, master stations for data processing, and geostationary satellites to relay WAAS data. To increase navigation accuracy, WAAS generates ionospheric correction data and broadcasts it to its users. Ionospheric irregularities cause scintillation of GPS signal power and phase, which can interrupt radio signal reception and degrade the integrity and accuracy of technology applications that rely on the Global Navigation Satellite System (GNSS).
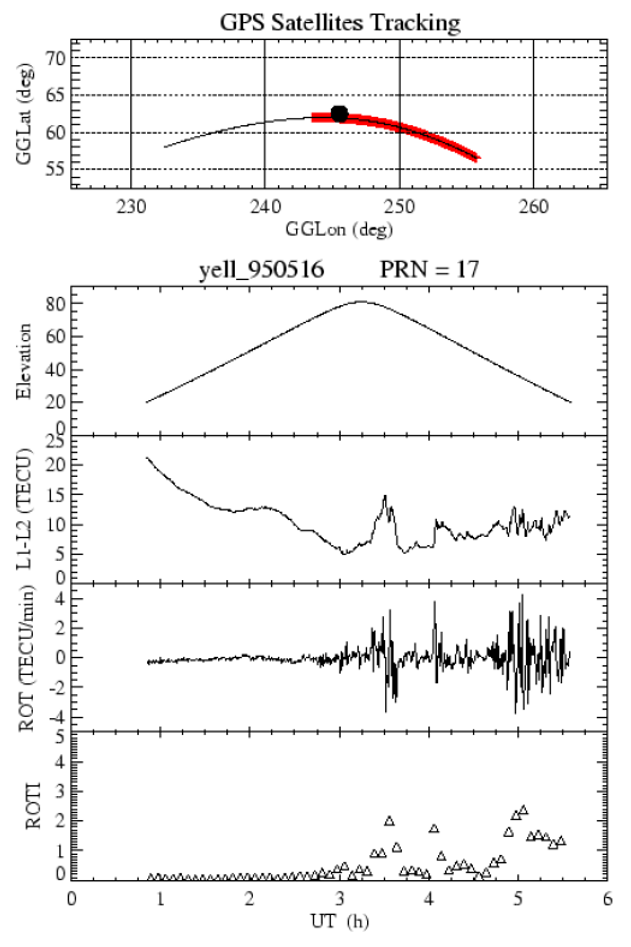
Ionospheric irregularities can be explained and measured as described by Figure 1. The progression of rate of total electron content (TEC) is measured as the rate of TEC (ROT). Both ROT and rate of TEC index (ROTI) are measurements of ionospheric irregularities that can cause L-band radio signal scintillations; the ROTI index is the standard deviation of ROT [2][3]. A value of ROTI at or near zero represents a low level of disturbances, while a high value represents the presence of ionospheric irregularities indicating a stormy period.
The goal of this research is to investigate which space weather and geophysical measurements are useful in machine-learning (ML) techniques for a prediction system that uses historical GPS data to predict the location, time, and intensity of concerning irregularities. The system is targeted to reduce the impact of scintillation effects on GNSS data and applications.
Correlation Analyses
The ionospheric data used for this analysis was ROTI data with 5-minute intervals. The ROTI data was obtained by processing GPS phase data collected at Fairbanks, Alaska (station name: FAIR, station coordinates: 64.98º geographic latitude and 212.5º geographic longitude). At each epoch, <ROTI> is obtained by averaging ROTI values over a number of satellites in view.
The first main parameter used was auroral electrojet ((AE)) indices derived from longitudinally distributed magnetic field data in the polar region. This data includes four indices:
- AU: The upper envelope expressing the strongest intensity of eastward auroral electrojets.
- AL: The lower envelope expressing the strongest intensity of westward auroral electrojets.
- AE:
- AO:


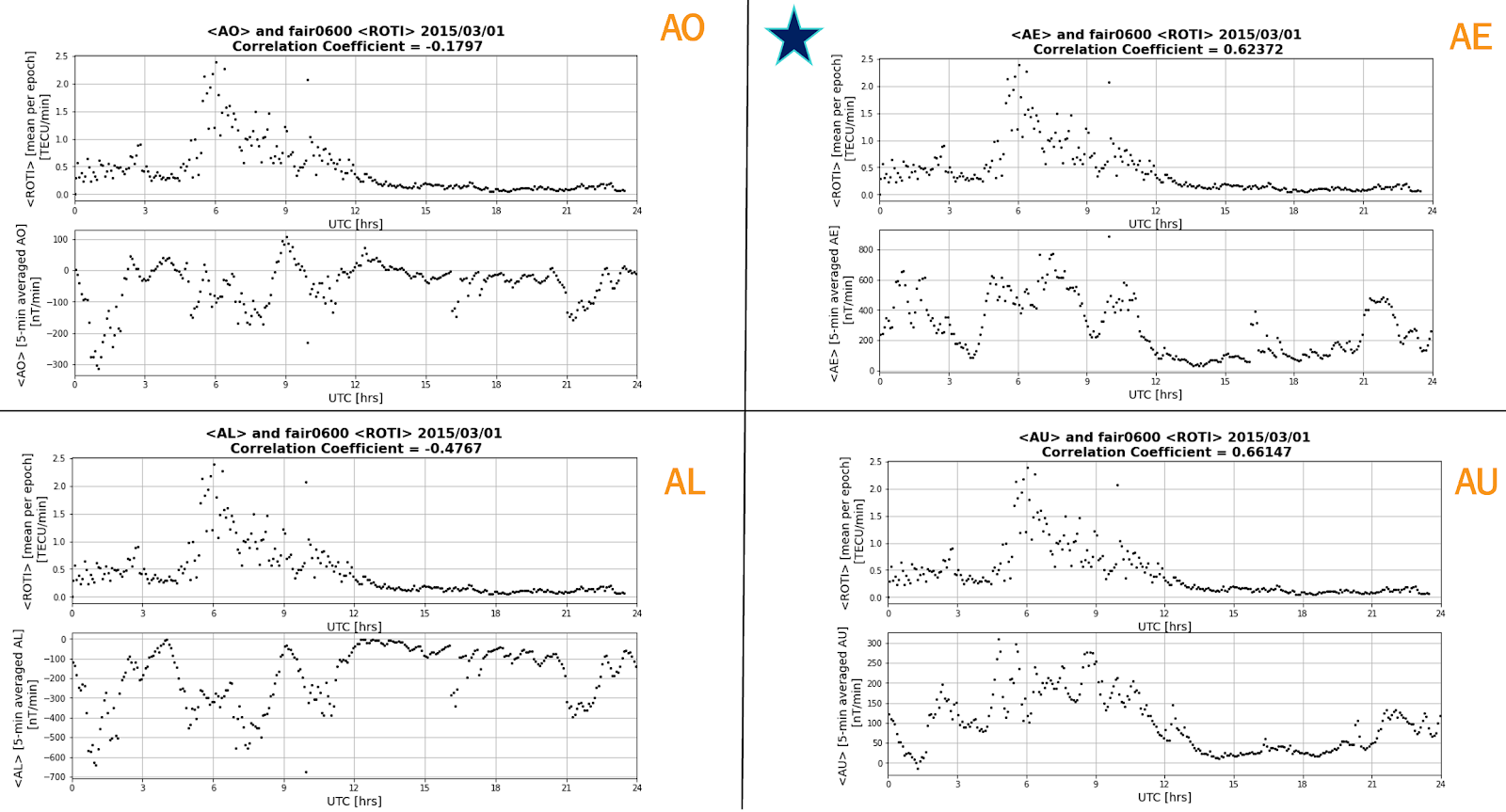
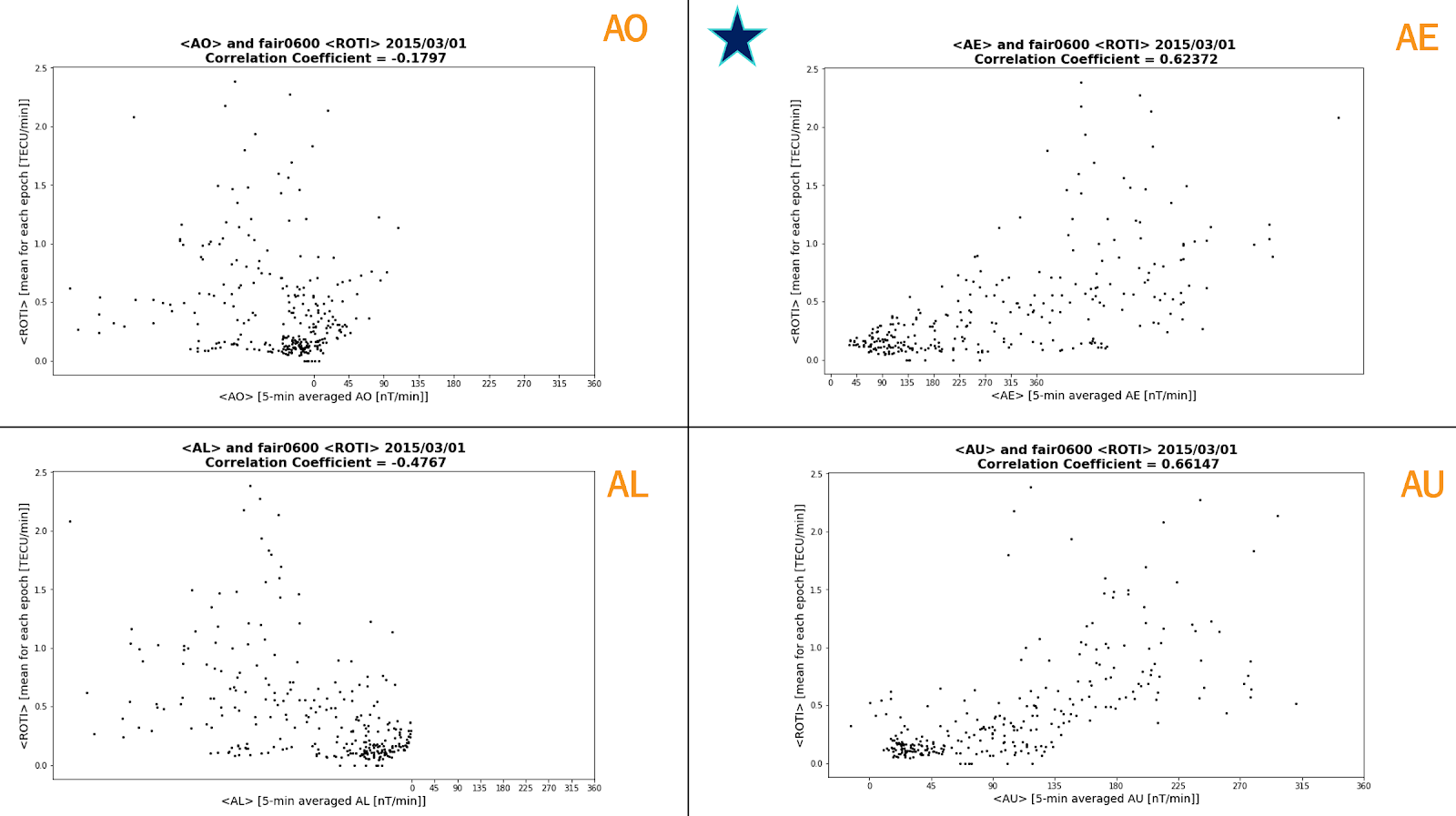
A correlation analysis was first conducted between the ROTI and (AE) data. On average, the <AE> index, averaged over 5-minute intervals, had a higher correlation with <ROTI>, though <AU> occasionally correlated more with <ROTI> such as the case for March 01, 2015 (Figure 2). In general, there were more complications with <AL> and <AO> indices, as is evident with the negative values in contrast to positive <ROTI> values. Additionally, while <AE> did correlate more with <ROTI>, the correlation coefficient was 0.63, indicating that there were periods of time where <AE> data was disturbed and <ROTI> was not. Furthermore, from Figure 3, it is apparent that the relationship between <AE> and ROTI is non-linear. Thus (AE) data is not ideal for forming <ROTI> predictions, since it is measured along many longitudes (twelve to be exact) while ROTI measures localized irregularities.
Since (AE) did not correlate well with <ROTI>, new data were needed. Localized magnetometer data, provided by the SuperMag Organization, was the next main parameter used. This data was collected at the Alaskan station of College (station name: CMO, station coordinates: 64.87º geographic latitude and 212.14º geographic longitude). To obtain a better correlation with <ROTI>, a combination of the magnetic field’s horizontal and vertical components was calculated and used: First, Bh = 
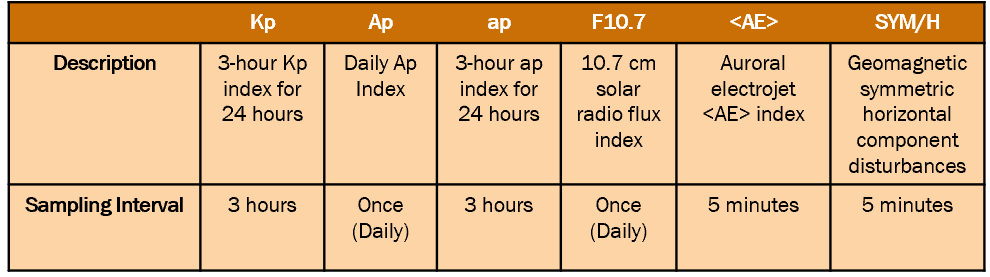
Additionally, several other measurements, such as solar radio flux, solar wind, IMF components, and geomagnetic field indices, were used for analysis, as shown below in Table 1.
Table 1: Parameters and Measurements
All the data used, including <<Bhz>> and <ROTI>, are measured in UTC. Tests were also conducted to determine if the correlation improves when data is compared at Local Solar Time using the following formula:
![LST = UTC[hours] + \frac{longitude[degrees]}{15}](https://s0.wp.com/latex.php?latex=LST+%3D+UTC%5Bhours%5D+%2B+%5Cfrac%7Blongitude%5Bdegrees%5D%7D%7B15%7D&bg=ffffff&fg=000&s=0&c=20201002)
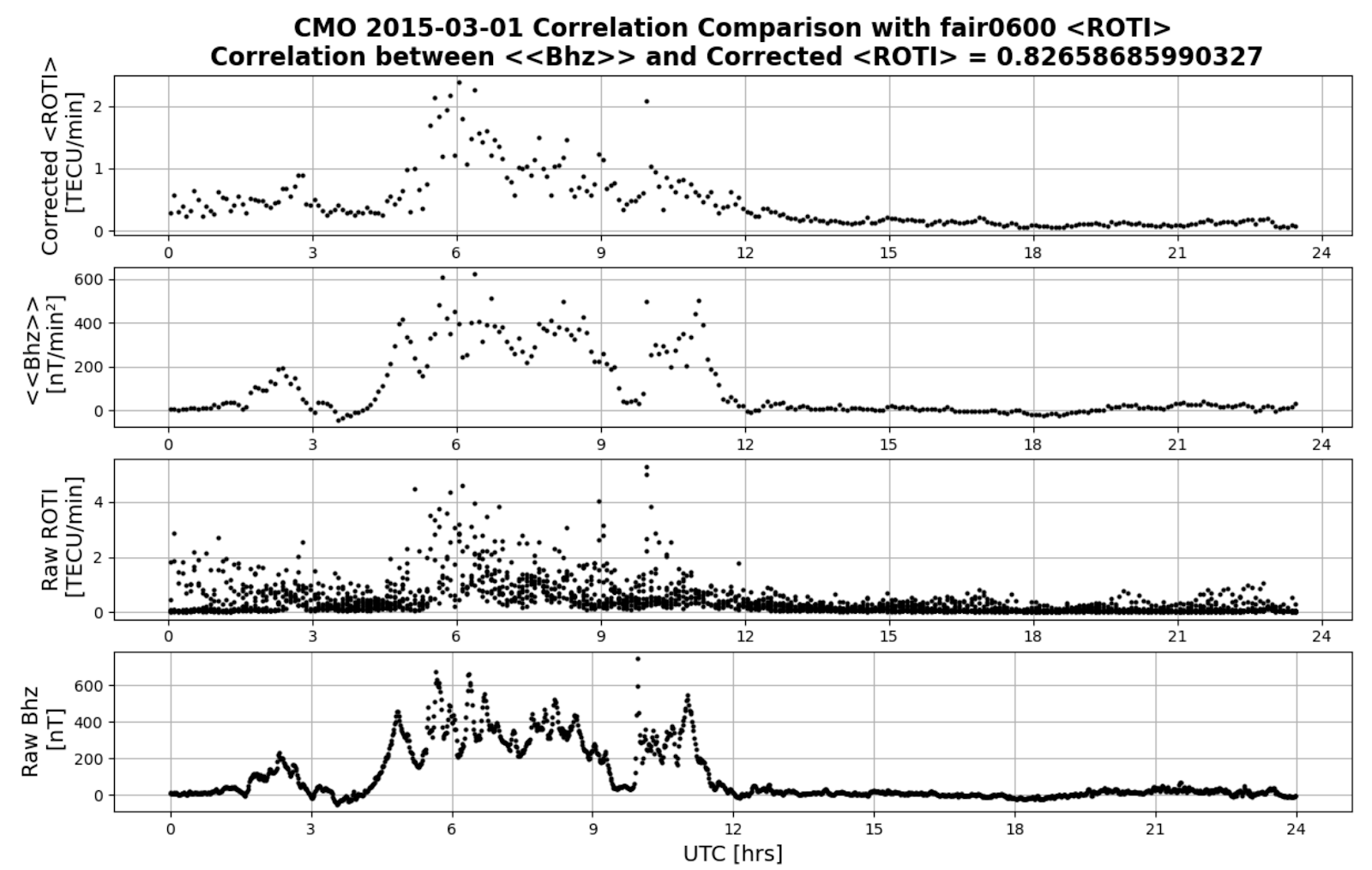
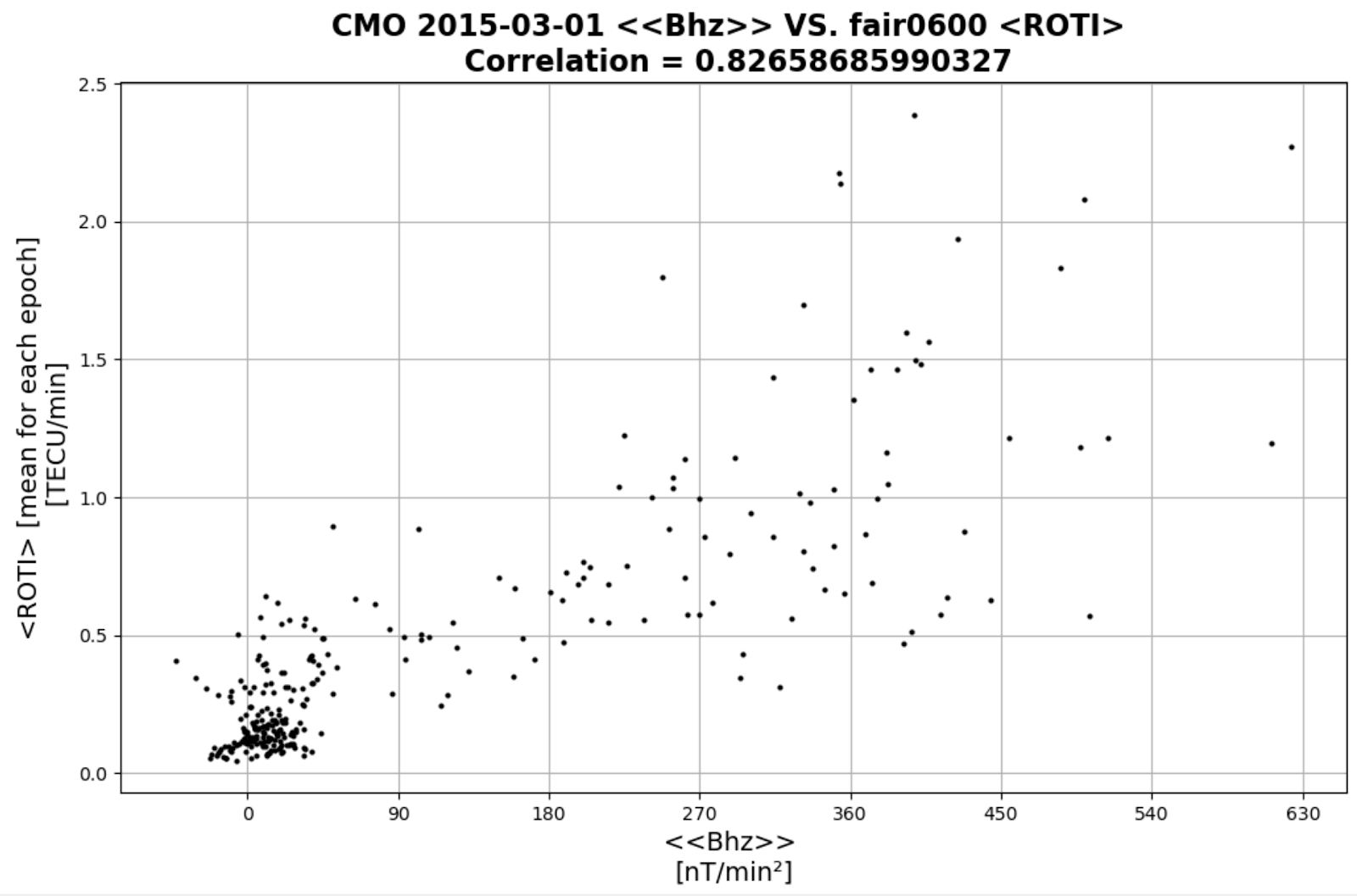
Using magnetometer data collected at the same longitude as the ROTI data gave an improved correlation. In fact, looking at the same day, March 01, 2015, the correlation between <<Bhz>> and <ROTI> is 0.82, an increase of 0.2 compared to using (AE) data. Referring to Figure 4, the periods of disturbed and undisturbed times match for both <<Bhz>> and <ROTI>. Additionally, Figure 5 shows a more linear relationship between <<Bhz>> and <ROTI> in comparison to that between (AE) and <ROTI>.
Machine-Learning and Ridge Regressions
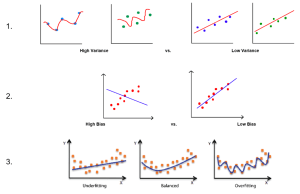
2. High bias in contrast to low bias where bias is related to a model failing to fit the training set [4][5].
3. The contrast between an under fitted, balanced, and overfit model [5].
Three integral components of a ML algorithm are variance, bias (regularization), and overfitting, as seen in Figure 6 [4]. Variance is a measure of how accurately a model can change when presented with a different data set. High variance is associated with a model failing to fit the testing dataset. Bias is the inability of a method to capture the true relationship of data. Typically, bias is used to develop a model that can predict targets for data that follow a general pattern, rather than a specific one. Bias is associated with a model failing to fit the training set of data. Finally, overfitting occurs when a polynomial with a higher degree than what is needed is used to model data. Overfitting causes a model to perform well for training samples but to fail when it comes to generalizing.
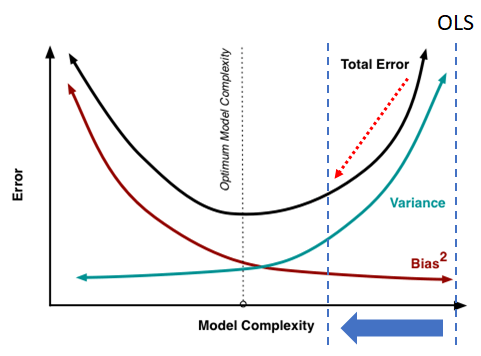
The algorithm used to produce <ROTI> predictions is a Ridge Regression. A Ridge Regression is a Linear Regression (sum of squares) with a small bias [4]. This results in a significant drop in variance. However, starting with a slightly deficient fit results in an improved long-term prediction since the same pattern that the model was trained on is not memorized. A Ridge Regression is ideal for working with data that shows multicollinearity tendencies, such as <ROTI> data. In comparison, an Ordinary Least Squares (OLS) model treats all variables equally and is unbiased. The OLS model therefore becomes more complex as the number of variables increases. As displayed in Figure 7, the optimal model complexity is at the middle of the plot, where the error is at its lowest. Unlike the OLS model, the regularization parameter of a Ridge Regression can be tuned to change the model’s coefficients and produce more accurate predictions.
The Ridge Regression has several variables and parameters:
- α = Hyperparameter that determines the regularization strength. The larger the alpha value, the stronger the regularization. A large alpha increases the bias of the model significantly. An alpha value equal to 1 is equivalent to a Linear Regression.
- w = Vector of coefficients
- B = Regression coefficients to be estimated
- e = Error residuals
- X = Matrix of independent variables (x)
- Y = Dependent variable (prediction)
The Ridge Regression equation, in matrix form, used to calculate desired predictions is shown in (1) [6].
Y = XB + e (1)
The loss function of the Ridge Regression is the linear least squares function, as shown in (2), and the regularization is given by the L2 norm, which calculates the distance of a vector coordinate from the origin of the vector in space. It is equivalent to the OLS model plus α multiplied by the summation of the squared coefficient values [4].

Overall, when calculating predictions, the Ridge Regression aims to minimize the loss function by finding a balance between minimizing the residual sum of squares as well as the coefficients (3) [4].

Coefficients of the Ridge Regression are calculated by first taking the cost function, performing some algebra, taking the partial derivative of the cost function with respect to w, and setting it equal to 0 to solve (4) [4].

The Ridge Regression model used to predict <ROTI> was programmed using Python and three main libraries: Pandas, Numpy, and Scikit-Learn. It was fit and tested on data from a total of 22 disturbed and stormy days with 18 days used for training and 4 days used for testing. The overall goal was to test which space weather and geophysical measurements would be useful for a ML prediction system. The test was performed with historical GPS and magnetometer data to predict the location, time, and intensity of concerned irregularities, under various geophysical and space weather conditions.
Two measures of performance were used to determine the accuracy of the Ridge Regression model: Root Mean Square Error (RMSE) and R squared (R2). RMSE is the average magnitude of the residuals, or error, and is represented by (5). It is optimal to obtain an RMSE as close to 0 as possible [7].







Experimental Results
As shown in Tables 2-4, many parameters and combinations of parameters were tested using a Ridge Regression model. The outputs of the Regression process include an ideal α value, the w vector, the Ridge Regression coefficients, the
Table 2: Ridge Regression Results (Part 1/3)
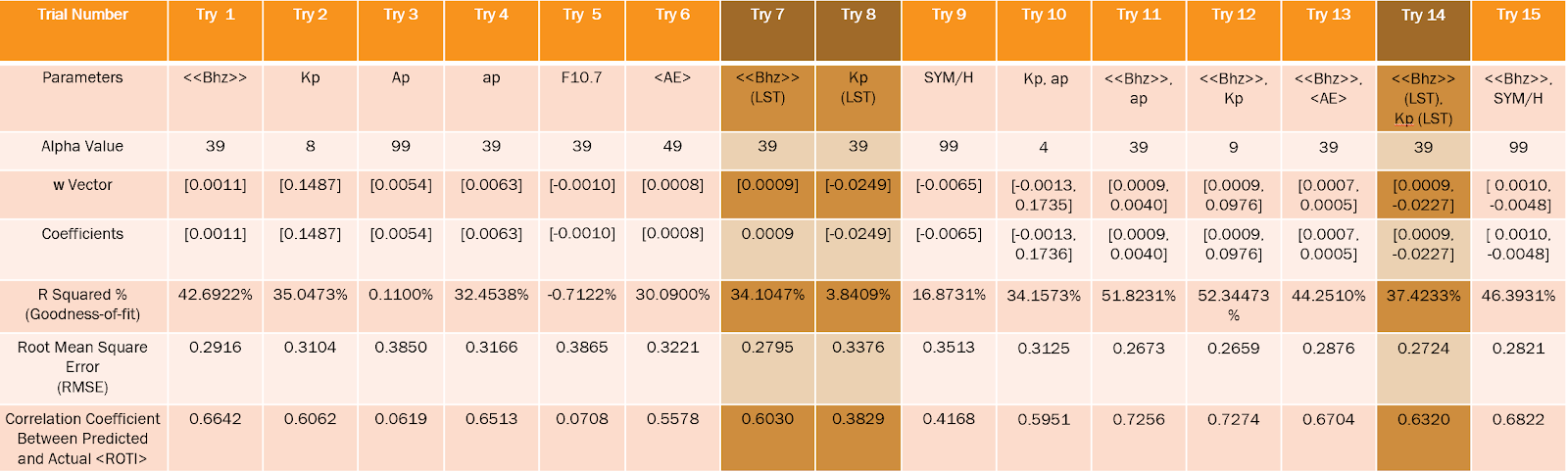
Table 3: Ridge Regression Results (Part 2/3)
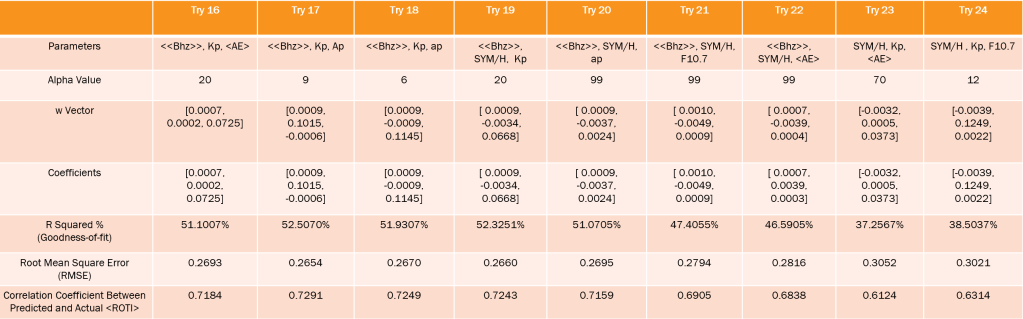
Table 4: Ridge Regression Results (Part 3/3)
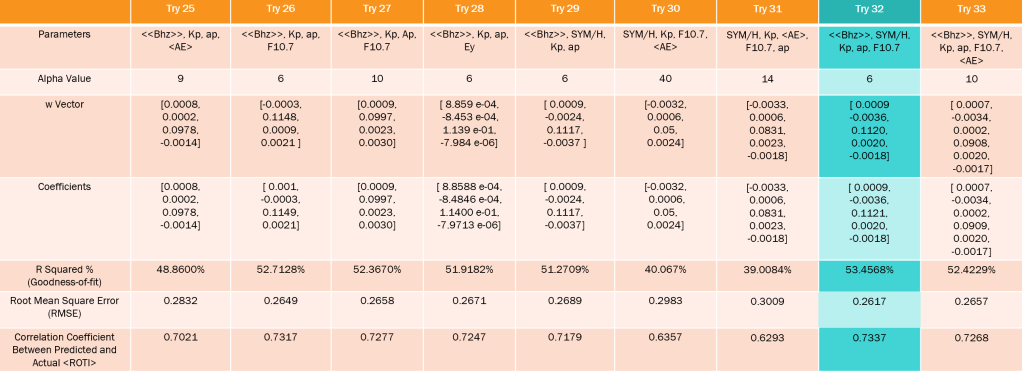 value and correlation coefficient between the predicted and actual <ROTI>.
value and correlation coefficient between the predicted and actual <ROTI>.The combination of parameters with the highest correlation coefficient and
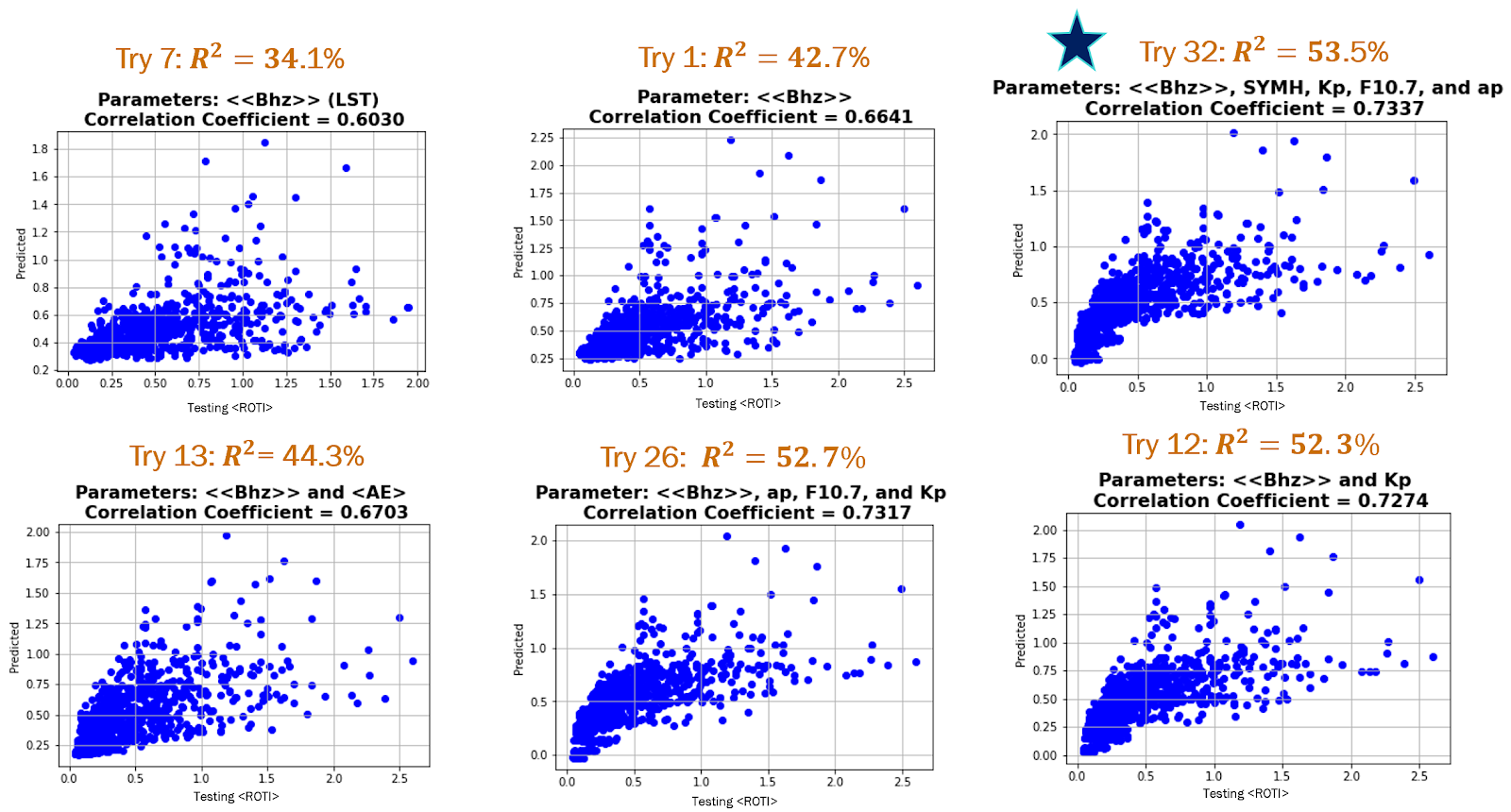
Conclusions
Since the largest
Understanding how and why these different physical phenomena are correlated is crucial in making accurate predictions. As the development of the ML algorithm continues, its output will aid and contribute to the representation and understanding of the variations of the ionospheric state. The goal for the algorithm, once it is implemented, is to predict the location, time, and intensities of ionospheric irregularities under various geophysical and space weather conditions, reducing the impact of ionospheric scintillation on receptions of GNSS signals and data and improving navigation systems.
Acknowledgements
The author would like to thank Dr. Xiaoqing Pi for providing research guidance, technical assistance, and for processing and providing the ROTI data; Caltech Northern California Associates for the fellowship; Peyman Tavallali, Jet Propulsion Laboratory, California Institute of Technology, for suggesting the use of the Ridge Regression Algorithm; IGS for the management of the GNSS Data Archives; and SuperMag Organization for the distribution of magnetometer data.
References
- (2020, August 03). Retrieved from https://www.faa.gov/about/office_org/headquarters_offices/ato/service_units/techops/navservices/gnss/waas/
- Pi, X., A. J. Mannucci, U. J. Lindqwister, and C. M. Ho, Monitoring of global ionospheric irregularities using the worldwide GPS network, Geophys. Res. Lett., 24, 2283, 1997.
- Pi, X., Mannucci, A.J., Valant-Spaight, B., Bar-Sever, Y., Romans, L. J., Skone, S., Sparks, L., Hall, G. Martin, “Observations of Global and Regional Ionospheric Irregularities and Scintillation Using GNSS Tracking Networks,” Proceedings of the ION 2013 Pacific PNT Meeting, Honolulu, Hawaii, April 2013, pp. 752-761.
- Maklin, C. (2019, August 19). Ridge Regression Python Example. Retrieved from https://towardsdatascience.com/ridge-regression-python-example-f015345d936b
- Qshick. (2019, January 03). Ridge Regression for Better Usage. Retrieved from https://towardsdatascience.com/ridge-regression-for-better-usage-2f19b3a202db
- Chapter 335 Ridge Regression – NCSS .Chapter 335 Ridge Regression Introduction Ridge Regression is – [PDF Document]. (n.d.). Retrieved from https://fdocuments.in/document/chapter-335-ridge-regression-ncss-chapter-335-ridge-regression-introduction.html
- Singh, D. (2019, May 17). Deepika Singh. Retrieved from https://www.pluralsight.com/guides/linear-lasso-ridge-regression-scikit-learn
- Magnetometer Data. (n.d.). Retrieved from http://supermag.jhuapl.edu/mag/?fidelity=low&start=2001-01-01T00:00:00.000Z&interval=1:00:00
