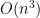Author: Berlin Chen
Mentors: Hai Nguyen, Derek Posselt
Editor: Michael Yao
Abstract
We used Convolutional Neural Networks (CNNs) to emulate the physics of the atmosphere in order to bypass solving partial-differential equations (PDEs) explicitly, which cuts down on computational cost. This is important because in the past, the models used to produce reliable weather forecasts required a computationally complex calibration.
We let the CNNs learn on a 4-dimensional (longitude x latitude x height x time) geophysical dataset, with a separate CNN for each height index. After a series of experiments we conducted following implementation, we found that zero-padding the data, varying time scale, and changing sample space had little effect on the CNNs’ performance, and that there was little correlation between training data size and error. We also observed that given the same training-data size, the CNNs with a more complex configuration (more sets of weights) actually performed worse.
1 Background
1.1 Variability Quantification
Reliability of weather forecasts has a variety of important consequences. Certainly, reliable weather forecasts bring people convenience of knowing when to bring an umbrella or when to stay at home rather than go to the supermarket. Our economy also has a stake in reliable weather forecasts, as natural disasters incur billions of dollars in damage each year [1].
Improving the reliability of weather forecasts, however, can be a challenge. In particular, initial conditions of the forecast model (such as referential sea-level pressure) can differ from reality. Because the underlying mechanisms governing the atmospheric behavior can be unstable, small changes in initial conditions can lead to wildly different predictions.
One way to characterize variability is to treat the value of each parameter not as a unique value, but rather as a probability distribution of values. In this context, prediction is the calibration of the probabilities of a parameter having certain values in the future, given the current measurement of some parameters. Bayes’ theorem allows us to quantify this information:

where 


Repeated simulations evaluating the sensitivity of 
1.2 Machine Learning and Neural Networks
Machine learning essentially describes the process of approximating input-output relationships. Toddlers learn by observing and drawing connections (as opposed to memorizing formal rules). In the same way, we can analogously design a procedure that directs computers how to acquire information about a function, instead of coming up with hard-and-fast rules for arriving at a solution. In practice, this means that, instead of computing desired outputs from given inputs, one would feed into the computer many input-output pairs and let the computer learn the mapping. This technique is highly relevant when the function is too complex to solve analytically 
The machine-learning technique that we used to realize this concept is called a 













To implement a typical neural network model, we must first train the model on many input-target pairs by running the neural network with some or all of the inputs. We may determine the neural network’s performance by using some error measures (such as the mean squared error, or MSE, of the neural network’s outputs with respect to corresponding targets). To the minimize error measures, we may update the neural network’s weights.
Generally, a model is only as good as the training data, and so the neural-network approach is domain specific and cannot be easily generalized from, say, one geographical region to another [4]. The model, however, is advantageous in speed. Using machine-learning techniques, we bypass the task of solving PDEs (partial differential equations), which is traditionally where the bulk of computation takes place. Consequently, the runtime of neural-net predictions will be orders of magnitude less than those of PDE solvers. Hence, if our speculation is sound, then neural nets could address the need for speeding up repeated simulations of differing initial values, which, as mentioned earlier, is a crucial contributor to the characterization of weather-forecast uncertainty.
1.3 Convolutional Neural Nets (CNN)
The distinctive feature of a CNN, which is the type of neural networks we used for this project, is the inclusion of one or more convolutional layer(s). To understand how the output of a convolutional layer is related to its inputs, one can imagine applying (
It has been shown that a CNN can achieve remarkable accuracy when it is applied to the task of labeling certain features in some spatially-meaningful data (such as images and videos) [9]. Therefore, since the atmospheric behavior for the kinds of data we use is also spatially meaningful, a CNN is a promising candidate.
1.4 Nature Run Dataset
For our experiments, we used the Nature Run dataset. It is generated by the model in 5-minute intervals from 00 UTC 22 Nov 2006 to 06 UTC 23 Nov 2006 (a total of 30 hours) 



2 Experiments
2.1 Preliminary Results
Prior to designing and running the experiments, we trained the CNNs on the time interval from the 

 vertical () index. The heatmap to the left is CNN’s prediction, and the heatmap to the right is the target. The heatmap in the middle is their difference. All values are standardized.
vertical () index. The heatmap to the left is CNN’s prediction, and the heatmap to the right is the target. The heatmap in the middle is their difference. All values are standardized.To measure loss, we divided the variance of the residual (


Additionally, we trained the CNNs on the interval from the 6th to the 30th hour of Nature Run and let it predict the same 24-hour interval it was trained on (and so the input corresponding to the zeroth time step is the ground truth while all subsequent inputs are predictions made by the CNNs), in order to gauge how well the CNNs may generalize inputs generated by themselves. Figure 5 illustrates snapshots taken at various time steps, along with the plot of the loss as a function of time steps predicted 

2.2 Variable Testing
Having these preliminary results, we ran a series of five experiments in an effort to understand how various parameters affect the behavior of the CNN.
First, we tested whether using zero padding significantly affects CNN’s prediction accuracy. 
To establish basis for comparison, we introduced another padding scheme: instead of filling in zeros, we filled in the ground truth (
Secondly, we tested whether training the CNNs to output the spatial data that is two or more time steps away from the input data (the default is one time step) would yield better results (
To examine this possibility, we trained two versions of CNNs, 
Thirdly, we tested how well the model learned by our CNNs extrapolates to time intervals outside of the training data’s time interval (ideally, the model learned by the CNNs would generalize to any given time interval). To that end, we compared predictions where the first input is taken from the training data, to predictions where the first input lies outside the training time-step interval. In this case, comparison entails using the same CNN models to predict different ranges of time steps, one inside and one outside the training time-step interval, and observing the discrepancy in accuracy. Based on the result (see Figure 8), we observed very little difference in CNNs’ performance. In this case, even as predictions were made on different time intervals, the quality of prediction does not differ significantly. This supports that the time interval for predictions has little influence on the quality of predictions.
Fourth, we assessed the performance of the CNNs as a function of the available sample size. This is motivated by the observation that training the CNNs with all available training data until convergence is demonstrably infeasible given our time budget and computing resources. To that end, we trained the CNNs given 1, 2, 5, and 10 percent of all available training data (all configurations have a training time-step interval of six hours).
Based on our result (see Figure 9), we observed a lack of correlation between prediction accuracy and training data size. Although this does not inform us about the performance of CNNs with training data larger than 10 percent of total available data, the lack of correlation between prediction accuracy and training data size at least provides a reason to believe that the CNNs trained with 2 percent of total available data do not perform consistently worse than those trained with 10 percent.
Finally, we assessed how the CNN’s prediction accuracy would be affected if we make the CNN’s architecture more complex 
From Figure 10, it seems clear that CNNs with higher complexity have lower prediction accuracy. A possible explanation is that, in the case of more complex CNNs, there are more parameters in the CNNs to tune, and so the space of all possible models (the 
Figure 4 provides a visual summary of all experiments mentioned.


 in this case refers to the temporal index. For each temporal index, the upper left panel is the CNN’s prediction, the upper left is the target, the lower left is the difference between prediction and truth, and the lower right is the loss as a function of temporal indices. (Note that the y-axis is inverted.)
in this case refers to the temporal index. For each temporal index, the upper left panel is the CNN’s prediction, the upper left is the target, the lower left is the difference between prediction and truth, and the lower right is the loss as a function of temporal indices. (Note that the y-axis is inverted.)


training time interval and the other lying outside of it (Experiment 3).
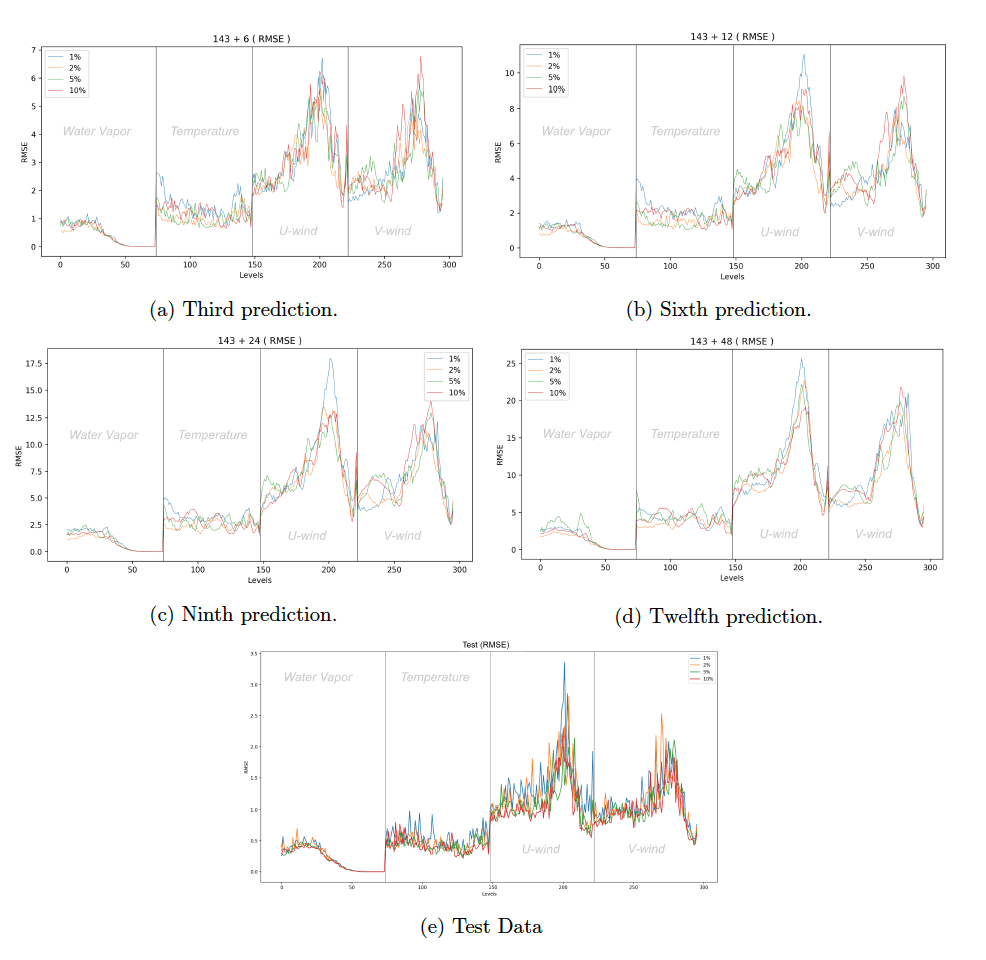
inputs being the test data.

Future Works
Based on our findings, we are confident that CNNs could be refined as an emulator that efficiently quantifies uncertainties, a task crucial to reliable weather forecasts. Besides the questions we addressed in this research, there are other inquiries relevant in our assessment of our CNN implementation. For instance, we would like to know whether tuning hyperparameters, such as the learning rate for the CNNs, would lead to better performance. Also, for the CNNs to be an effective emulator for longer time intervals, we would like to further investigate principle factors that contribute to the blurring of prediction overtime. So far, we provided only qualitative assessments, and so further research is needed in order to identify the kind of quantitative assessments suitable for our purpose. Additionally, we would like to assess the CNNs’ performance beyond the Nature Run dataset.
Acknowledgements
The author would like to thank his mentors, Hai Nguyen and Derek Posselt, for their mentorship, expertise, and support. The author also would like to thank Amy Braverman, the Principle Statistician of JPL, for making this opportunity possible and for offering numerous helpful advices. The author owes much to the helpful feedback and support he received from JPL’s Uncertainty Quantification group, as well as the technical support he benefited from Bob P. Thurstans, a member of the Technical Staff at JPL’s Science Division. The author is also grateful for the abundant resources and opportunities available to him as a participant of the Caltech SURF program. Finally, the author would like to thank his family and colleagues, with whom he shares the same workspace, for their constant presence and support.
References
[1] Denning, Marty. “The Impact of Accurate Weather Forecasting Data For Business.” The Weather Company. October 27, 2015. Accessed October 20, 2017. https://business.weather.com/blog/the-impact-of-accurate-weather-forecasting-data-for-business.
[2] Rappaport, Edward N. “Loss of Life in the United States Associated with Recent Atlantic Tropical Cyclones.” 
[3] Smith, Ralph C. 
[4] Olah, Christopher. “Calculus on Computational Graphs: Backpropagation.” Colah’s blog. August 31, 2015. Accessed October 21, 2017. http://colah.github.io/posts/2015-08-Backprop.
[5] Mas, Jean, and Juan Flores. “The application of artificial neural networks to the analysis of remotely sensed data.” 
[6] Hagan, Martin T., Howard B. Demuth, Mark Hudson. Beale, and Orlando De Jesús. 
[7] Skamarock, William C., Joseph B. Klemp, Jimy Dudhia, David O. Gill, Dale M. Barker, Micheal G. Duda, Xiang-Yu Huang, Wei Wang, and Jordan G. Powers. “A Description of the Advanced Research WRF Version 3.” NCAR TECHNICAL NOTE, June 2008. http://www2.mmm.ucar.edu/wrf/users/docs/arw_v3.pdf
[8] Karpathy, Andrej. “Convolutional Neural Networks (CNNs / ConvNets).” CS231n Convolutional Neural Networks for Visual Recognition. Accessed October 20, 2017. http://cs231n.github.io/convolutional-networks/
Footnotes